
たとえば
- 最果てグローブ
- 無駄毛ロンガー
- ビックリ弁当箱
- 赤
- 青
- 黒
- 白
- 緑
それぞれどれだけ売れたのかを集計とかやってみる。
似たような作業が実務で発生し、SQL未熟者の俺としては、これはぜひ覚えたいと思い、いろいろ試行錯誤してみたら出来たので、備忘録がてらかいておく。
結果として、イメージされる表にするとこういう感じ。
| 商品名 | 白 | 黒 | 赤 | 青 | 緑 |
|---|---|---|---|---|---|
| ビックリ弁当箱 | 1 | 1 | 2 | 1 | 2 |
| 最果てグローブ | 2 | 2 | 2 | 1 | 0 |
| 無駄毛ロンガー | 1 | 0 | 2 | 1 | 2 |
都道府県別に男女数を出すような、こんな感じをイメージしてもよい。
| 都道府県 | 男 | 女 |
|---|---|---|
| 東京都 | 5 | 8 |
| 神奈川県 | 4 | 7 |
| 千葉県 | 0 | 31 |
マスタテーブルつくって説明すると面倒くさいので、直接商品名、色名をインサートするとし、テーブルを以下のように作っておく。
CREATE TABLE IF NOT EXISTS `history` ( `id` int(5) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `color` varchar(255) NOT NULL, `price` int(10) unsigned NOT NULL, `created` datetime NOT NULL, `modified` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `name` (`name`,`price`,`created`,`modified`,`color`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='購入履歴' AUTO_INCREMENT=1 ;このテーブルに、購入履歴がばしばしインサートされると想定しておく。
で、先に答えを言うと、実はSQLは1個でOKと言う事が分かった。
さらに処理速度もSQLを複数回吐くより段違いに早い。
まずはダミーデータをいれて試してみよう。
以下のSQLを実行だ。
INSERT INTO `history` (`id`, `name`, `color`, `price`, `created`, `modified`) VALUES (19, 'ビックリ弁当箱', '青', 512, '2010-06-17 23:03:40', NULL), (4, 'ビックリ弁当箱', '白', 525, '2010-06-17 23:03:40', NULL), (16, 'ビックリ弁当箱', '緑', 525, '2010-06-17 23:03:40', NULL), (17, 'ビックリ弁当箱', '緑', 525, '2010-06-17 23:03:40', NULL), (2, 'ビックリ弁当箱', '赤', 525, '2010-06-17 23:03:40', NULL), (12, 'ビックリ弁当箱', '赤', 525, '2010-06-17 23:03:40', NULL), (6, 'ビックリ弁当箱', '黒', 525, '2010-06-17 23:03:40', NULL), (8, '最果てグローブ', '白', 525, '2010-06-17 23:03:40', NULL), (14, '最果てグローブ', '白', 525, '2010-06-17 23:03:40', NULL), (1, '最果てグローブ', '赤', 525, '2010-06-17 23:03:40', NULL), (7, '最果てグローブ', '赤', 525, '2010-06-17 23:03:40', NULL), (15, '最果てグローブ', '青', 525, '2010-06-17 23:03:40', NULL), (3, '最果てグローブ', '黒', 525, '2010-06-17 23:03:40', NULL), (11, '最果てグローブ', '黒', 525, '2010-06-17 23:03:40', NULL), (10, '無駄毛ロンガー', '白', 525, '2010-06-17 23:03:40', NULL), (5, '無駄毛ロンガー', '緑', 525, '2010-06-17 23:03:40', NULL), (18, '無駄毛ロンガー', '緑', 525, '2010-06-17 23:03:40', NULL), (9, '無駄毛ロンガー', '赤', 525, '2010-06-17 23:03:40', NULL), (13, '無駄毛ロンガー', '赤', 525, '2010-06-17 23:03:40', NULL), (20, '無駄毛ロンガー', '青', 525, '2010-06-17 23:03:40', NULL);この状態で、たとえば「ビックリ弁当箱」を色別にそれぞれ何個売れたのかを集計するには、単純にcountを使えばよい。
select name, color, count(color) as num from history where name = 'ビックリ弁当箱' group by color結果はこうなる。
| name | color | num |
|---|---|---|
| ビックリ弁当箱 | 白 | 1 |
| ビックリ弁当箱 | 緑 | 2 |
| ビックリ弁当箱 | 赤 | 2 |
| ビックリ弁当箱 | 青 | 1 |
| ビックリ弁当箱 | 黒 | 1 |
ここでは、色が行ではなく列として表示されてしまう。
このまま商品をあと二つ増やして出力しても、ただ行がたくさん縦に並んだだけの表になるだけで、見た目よろしくない。
これをどうにかして項目名として横に展開し、その集計を行ってみる。
まず使う関数としては、条件を使って色を判別し、指定した色なら1を(then)、そうでなければnullを(else)数える事にする。
数えるのでcount()を使う。そしてcount()の中身で条件を指定する。
ここで使うのはCASE文。このCASE文は覚えるとグレートに便利なので、今後ともたくさん使うことになるかも。
まず条件としては 色が白の場合を考えてみる。その場合
case when color='白'となる。
この条件が正しい場合1を返し、正しくない場合はnullを返す。
case when color='白' then 1 else null endそして返した値、もしくはnullをcount()で数えるという処理だ。
count(case when color='白' then 1 else null end)で、これをwhere句ではなくselect句でやる。つまり、1つのフィールドとして設定すれば、色が列にならずに行として、つまり項目名になってくれる。
select count(case when color='白' then 1 else null end) from historyこのままでは項目名が条件式になってしまうので、asをつかって別名を与える。
select count(case when color='白' then 1 else null end) as '白' from historyこれをそのまま実行すると、
| 白 |
|---|
| 4 |
と表示されるだろう。
このcount()はひとつの項目としてのフィールドなので、連続で記述すれば、色を全部表示させることが出来る。
select count(case when color='白' then 1 else null end) as '白', count(case when color='黒' then 1 else null end) as '黒', count(case when color='赤' then 1 else null end) as '赤', count(case when color='青' then 1 else null end) as '青', count(case when color='緑' then 1 else null end) as '緑' from history結果はこうなったはずだ。
| 白 | 黒 | 赤 | 青 | 緑 |
|---|---|---|---|---|
| 4 | 3 | 6 | 3 | 4 |
なかなか目的に近づいた感じになった。よろしおますよ!
しかし、これらの数値は全商品をあわせてカウントされてしまっている。
実際には白は4が1個ではなくて、
- 最果てグローブ(白):2
- ビックリ弁当箱(白):1
- 無駄毛ロンガー(白):1
となると、次にやるべき事は、nameフィールドをselect句にいれる事ではないか?
早速いれてみる。
select name, count(case when color='白' then 1 else null end) as '白', count(case when color='黒' then 1 else null end) as '黒', count(case when color='赤' then 1 else null end) as '赤', count(case when color='青' then 1 else null end) as '青', count(case when color='緑' then 1 else null end) as '緑' from history;さて、結果はどうだろう。
| name | 白 | 黒 | 赤 | 青 | 緑 |
|---|---|---|---|---|---|
| ビックリ弁当箱 | 4 | 3 | 6 | 3 | 4 |
これはこれは、なんだかテキトーな商品名が勝手に選択されてしまったようだ。しかも1個だけ。
こうなってしまうのはちゃんと理由がある。
nameをグループ化してないからだ。
グループ化すると、重複を省き、nameの個数を調べる事が分かる。
あらかじめ商品としてnameには3種類しかないので3が答えというのは分かっているが、自分の脳みそが理解していても、コンピュータはしっかり教えて揚げないと、何もしてくれない。
というわけで、グループ化してみる。
select name as '商品名', count(case when color='白' then 1 else null end) as '白', count(case when color='黒' then 1 else null end) as '黒', count(case when color='赤' then 1 else null end) as '赤', count(case when color='青' then 1 else null end) as '青', count(case when color='緑' then 1 else null end) as '緑' from history group by nameこれを実行すると、
| 商品名 | 白 | 黒 | 赤 | 青 | 緑 |
|---|---|---|---|---|---|
| ビックリ弁当箱 | 1 | 1 | 2 | 1 | 2 |
| 最果てグローブ | 2 | 2 | 2 | 1 | 0 |
| 無駄毛ロンガー | 1 | 0 | 2 | 1 | 2 |
となったはずだ。
ちなみに処理時間は
「クエリの実行時間 0.0008 秒」
だ。かなりよい。グレートによい。
ちなみにそれぞれの商品を、色を無視して単純に合計値を出したい場合なんかがあるとおもう。
つまり、こういう感じ。
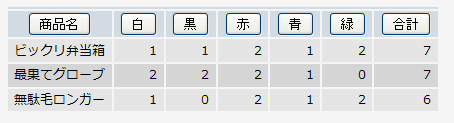
| 商品名 | 白 | 黒 | 赤 | 青 | 緑 | 合計 |
|---|---|---|---|---|---|---|
| ビックリ弁当箱 | 1 | 1 | 2 | 1 | 2 | 7 |
| 最果てグローブ | 2 | 2 | 2 | 1 | 0 | 7 |
| 無駄毛ロンガー | 1 | 0 | 2 | 1 | 2 | 6 |
俺の経験不足だろうけど、いろいろ試したらこういうSQLを吐く事になった。
select name as '商品名', count(case when color='白' then 1 else null end) as '白', count(case when color='黒' then 1 else null end) as '黒', count(case when color='赤' then 1 else null end) as '赤', count(case when color='青' then 1 else null end) as '青', count(case when color='緑' then 1 else null end) as '緑', case when name='ビックリ弁当箱' then sum(field(name, 'ビックリ弁当箱')) when name='最果てグローブ' then sum(field(name, '最果てグローブ')) when name='無駄毛ロンガー' then sum(field(name, '無駄毛ロンガー')) else null end as '合計' from history group by nameこれは少し不本意だ。
なぜなら、色はともかくとして、商品名を決め打ちでSQL内に記述しておく必要があるからだ。
とはいえ、実際には商品マスタのテーブルを用意し、色マスタのテーブルも用意しておくとすると、SQL自体をforeah()でループしながら生成し、出来上がったSQLを実行という動的生成な方法もとれる。
CakePHPだとこうなる。
$items = $this->Item->find('list');
$colors = $this->Color->find('list');
$sql = "select name as '商品名'";
$sql_chunk = array();
foreach($colors as $color) {
$sql_chunk[] = " count(case when color='{$color}' then 1 else null end) as '{$color}'";
}
$sql .= join(',', $sql_chunk);
$sql .= 'case ';
$sql_chunk = array();
foreach($items as $item) {
$sql_chunk[] = " when name='{$item}' then sum(field(name, '{$item}'))";
}
$sql .= join(' ', $sql_chunk);
$sql .= " else null"
. " end as '合計' "
. "from history "
. "group by name "
※実行してないからエラーでるかもなので、あながち完全に間違っているとは思ってない。
が、もっと修行すれば、よりスマートに(MS Accessのように)簡単に見た目が分かりやすいSQLを吐けるようになるかもしれない。
ちなみに実行時間は
クエリの実行時間 0.0010 秒
だった。ちょっとだけ遅くなったね。
あと関係ないけど、phpMyAdminで上記SQLを発行すると、結果が少し変更されるようだ。
なぜか、項目名がボタンになる。そしてクリックしてみたが、別にソートされるわけでもなく、何のためにボタンが付いたのか、やや不明である。
それから最後に、商品別に合計表示する(つまり右側に合計値を表示する)だけでなく、今度は色の合計(一番下の行に合計を表示する)をやってみようと思う。
これは実は簡単で、自宅にある古いMySQLのSQL実践本を調べたところ、面白いやり方があった。
group byにwith rollupを付けるだけだ。
select name as '商品名', count(case when color='白' then 1 else null end) as '白', count(case when color='黒' then 1 else null end) as '黒', count(case when color='赤' then 1 else null end) as '赤', count(case when color='青' then 1 else null end) as '青', count(case when color='緑' then 1 else null end) as '緑', case when name='ビックリ弁当箱' then sum(field(name, 'ビックリ弁当箱')) when name='最果てグローブ' then sum(field(name, '最果てグローブ')) when name='無駄毛ロンガー' then sum(field(name, '無駄毛ロンガー')) else null end as '合計' from history group by name with rollupこれを実行すると、結果は以下のようになる。
| 商品名 | 白 | 黒 | 赤 | 青 | 緑 | 合計 |
|---|---|---|---|---|---|---|
| ビックリ弁当箱 | 1 | 1 | 2 | 1 | 2 | 7 |
| 最果てグローブ | 2 | 2 | 2 | 1 | 0 | 7 |
| 無駄毛ロンガー | 1 | 0 | 2 | 1 | 2 | 6 |
| NULL | 4 | 3 | 6 | 3 | 4 | NULL |
非常に簡単に縦集計(つまりROOLUP)が横に並んだ。
ただ、NULLと表示されるのは格好悪い。
これに関してはいつかちゃんと調べたいと思う。
まぁとりあえずこれで目的は達成できた。
めでたしめでたし。




















{kind=link}
facebook
twitter
google+
fb share